Analyze a collection in memory#
Here, we’ll analyze the growing collection by loading it into memory.
This is only possible if it’s not too large.
If your data is large, you’ll likely want to iterate over the collection to train a model, the topic of the next page ().
import lamindb as ln
import lnschema_bionty as lb
import anndata as ad
💡 lamindb instance: testuser1/test-scrna
ln.track()
💡 notebook imports: anndata==0.9.2 lamindb==0.67.2 lnschema_bionty==0.39.0 scanpy==1.9.6
💡 saved: Transform(uid='mfWKm8OtAzp85zKv', name='Analyze a collection in memory', short_name='scrna4', version='1', type=notebook, updated_at=2024-01-24 13:38:09 UTC, created_by_id=1)
💡 saved: Run(uid='jLm8NAYWnHivSLma2vKR', run_at=2024-01-24 13:38:09 UTC, transform_id=4, created_by_id=1)
ln.Collection.df()
| uid | name | description | version | hash | reference | reference_type | transform_id | run_id | artifact_id | visibility | created_at | updated_at | created_by_id | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| id | ||||||||||||||
| 2 | 5rQPk6jQmbjiJEGvAHaw | My versioned scRNA-seq collection | None | 2 | BOAf0T5UbN_iOe3fQDyq | None | None | 2 | 2 | NaN | 1 | 2024-01-24 13:37:57.192065+00:00 | 2024-01-24 13:37:57.192085+00:00 | 1 |
| 1 | 5rQPk6jQmbjiJEGvZIIz | My versioned scRNA-seq collection | None | 1 | 9sXda5E7BYiVoDOQkTC0KB | None | None | 1 | 1 | 1.0 | 1 | 2024-01-24 13:37:38.413905+00:00 | 2024-01-24 13:37:38.413924+00:00 | 1 |
collection = ln.Collection.filter(
name="My versioned scRNA-seq collection", version="2"
).one()
collection.artifacts.df()
| uid | storage_id | key | suffix | accessor | description | version | size | hash | hash_type | n_objects | n_observations | transform_id | run_id | visibility | key_is_virtual | created_at | updated_at | created_by_id | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| id | |||||||||||||||||||
| 2 | vg8ACw5giDiVeFdVoFMA | 1 | None | .h5ad | AnnData | 10x reference adata | None | 853388 | eKH1ljAEh7Kd81-o2H4A7w | md5 | None | None | 2 | 2 | 1 | True | 2024-01-24 13:37:56.005447+00:00 | 2024-01-24 13:37:56.005467+00:00 | 1 |
| 1 | 5rQPk6jQmbjiJEGvZIIz | 1 | scrna/conde22.h5ad | .h5ad | AnnData | Human immune cells from Conde22 | None | 57612943 | 9sXda5E7BYiVoDOQkTC0KB | sha1-fl | None | None | 1 | 1 | 1 | True | 2024-01-24 13:37:36.544637+00:00 | 2024-01-24 13:37:38.410369+00:00 | 1 |
If the collection isn’t too large, we can now load it into memory.
Under-the-hood, the AnnData objects are concatenated during loading.
The amount of time this takes depends on a variety of factors.
If it occurs often, one might consider storing a concatenated version of the collection, rather than the individual pieces.
adata = collection.load()
The default is an outer join during concatenation as in pandas:
adata
AnnData object with n_obs × n_vars = 1718 × 36503
obs: 'cell_type', 'n_genes', 'percent_mito', 'louvain', 'donor', 'tissue', 'assay', 'artifact_uid'
obsm: 'X_pca', 'X_umap'
The AnnData has the reference to the individual artifacts in the .obs annotations:
adata.obs.artifact_uid.cat.categories
Index(['vg8ACw5giDiVeFdVoFMA', '5rQPk6jQmbjiJEGvZIIz'], dtype='object')
We can easily obtain ensemble IDs for gene symbols using the look up object:
genes = lb.Gene.lookup(field="symbol")
genes.itm2b.ensembl_gene_id
'ENSG00000136156'
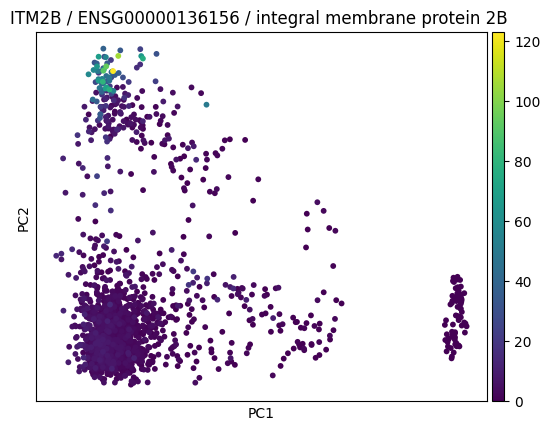
Let us create a plot:
import scanpy as sc
sc.pp.pca(adata, n_comps=2)
2024-01-24 13:38:12,489:INFO - Failed to extract font properties from /usr/share/fonts/truetype/noto/NotoColorEmoji.ttf: In FT2Font: Can not load face (unknown file format; error code 0x2)
2024-01-24 13:38:13,566:INFO - generated new fontManager
sc.pl.pca(
adata,
color=genes.itm2b.ensembl_gene_id,
title=(
f"{genes.itm2b.symbol} / {genes.itm2b.ensembl_gene_id} /"
f" {genes.itm2b.description}"
),
save="_itm2b",
)
WARNING: saving figure to file figures/pca_itm2b.pdf
We could save a plot as a pdf and then see it in the flow diagram:
artifact = ln.Artifact("./figures/pca_itm2b.pdf", description="My result on ITM2B")
artifact.save()
artifact.view_lineage()
Show code cell output

But given the image is part of the notebook, we can also rely on the report that we create when saving the notebook via the command line via:
lamin save <notebook_path>
To see the current notebook, visit: lamin.ai/laminlabs/lamindata/record/core/Transform?uid=mfWKm8OtAzp8z8